by Jeong-Yoon Lee
The Porto Seguro Safe Driver Prediction competition at Kaggle finished 2 days ago. 5,170 teams with 5,798 people competed for 2 months to predict if a driver will file an insurance claim next year with anonymized data.
Michael Jahrer, Netflix Grand Prize winner and Kaggle Grandmaster, took the lead from the beginning and finished #1. He graciously shared his solution right after the competition. Let’s check out his secret sauce. (This was initially posted on the Kaggle forum and reposted here with minor format changes with permission from him.)
Thanks to Porto Seguro to provide us with such a nice, leakage-free, time-free and statistical correct dataset.
A nice playground to test the performance of everything, this competition was stat similar to Otto, like larger testset than train, anonymous data, but differ in details.
I wanna dive straight into solution.
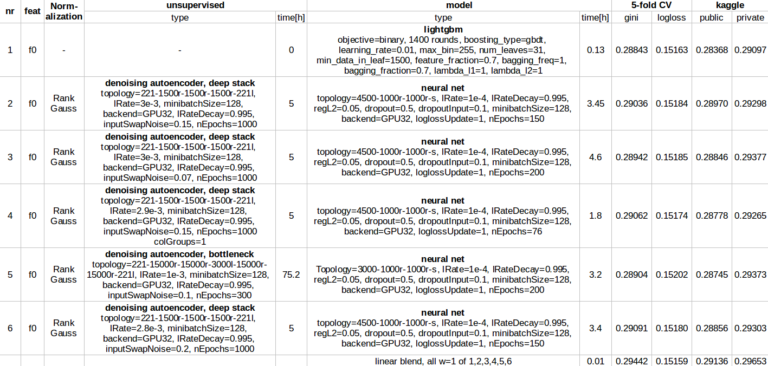
It’s a blend of 6 models. 1x lightgbm, 5x nn. All on same features, I just removed *calc and added 1-hot on *cat. All neural nets are trained on denoising autoencoder hidden activation, they did a great job in learning a better representation of the numeric data. lightgbm on raw data. Nonlinear stacking failed, simple averaging works best (all weights=1).
That’s the final 0.2965 solution. 2 single models would have been enough to win (#1 + #2 give me 0.29502 on private).
The complete list of models in the final blend:
Font is a bit small, you need to increase the zoom with ctrl (+).
The difference to my private .2969 score is I added bagging versions nBag=32 of the above mentioned 6 models, all weight=1, and Igor’s 287 script with weight=0.05. Was not really worth the effort for .2965 -> .2969 gain huh!? I selected these 2 blends at the end.
I dislike this part most, my creativity is too low for an average competition lifetime, also luck plays huge role here. Therefore I like representation learning, its also an step towards AI.
Basically I removed calc, added 1-hot to *cat features. That’s all I’ve done. No missing value replacement or something. This is feature set “f0” in the table. This ends up in exactly 221 dense features. With single precision floats its 1.3GB RAM (1e-94221(595212+892816)).
Thanks to the public kernels (wheel of fortune eg.) that suggest to remove *calc features, I’m too blind and probably would not have figured this out by myself. I never remove features.
5-fold CV as usual. Fixed seed. No stratification. Each model has own rand seed in CV (weight init in nn, data_random_seed in lightgbm). Test predictions are arithmetic averages of all fold models. Just standard as I would use for any other task. Somebody wrote about bagging and its improvements, I spend a week in re-training all my models in a 32-bag setup (sampling with replacement). Score only improved a little.
Input normalization for gradient-based models such as neural nets is critical. For lightgbm/xgb it does not matter. The best what I found during the past and works straight of the box is “RankGauss”. Its based on rank transformation. First step is to assign a linspace to the sorted features from 0..1, then apply the inverse of error function ErfInv to shape them like Gaussian, then I subtract the mean. Binary features are not touched with this transformation (eg. 1-hot ones). This works usually much better than standard mean/std scaler or min/max.
Denoising autoencoders (DAE) are nice to find a better representation of the numeric data for later neural net supervised learning. One can use train+test features to build the DAE. The larger the testset, the better 🙂 An autoencoder tries to reconstruct the inputs features. So features = targets. Linear output layer. Minimize MSE. A denoising autoencoder tries to reconstruct the noisy version of the features. It tries to find some representation of the data to better reconstruct the clean one.
With modern GPUs we can put much computing power to solve this task by touching peak floating point performance with huge layers. Sometimes I saw over 300W power consumption by checking nvidia-smi.
So why manually constructing 2,3,4-way interactions, use target encoding, search for count features, impute features, when a model can find something similar by itself?
The critical part here is to invent the noise. In tabular datasets we cannot just flip, rotate, sheer like people are doing this in images. Adding Gaussian or uniform additive / multiplicative noise is not optimal since features have different scale or a discrete set of values that some noise just didn’t make sense. I found a noise schema called “swap noise”. Here I sample from the feature itself with a certain probability “inputSwapNoise” in the table above. 0.15 means 15% of features replaced by values from another row.
Two different topologies are used by myself. Deep stack, where the new features are the values of the activations on all hidden layers. Second, bottleneck, where one middle layer is used to grab the activations as new dataset. This DAE step usually blows the input dimensionality to 1k..10k range.
You might think I am cheating when using test features too for learning. So I’ve done an experiment to check the effectiveness of unsupervised learning without test features. For reference I took model #2, public:0.28970, private:0.29298. With exactly same params it ends up in a slightly weaker CV gini:0.2890. public:0.28508, private:0.29235. Private score is similar, public score is worse. So not a complete breakdown as expected. Btw total scoring time of the testset with this “clean” model is 80[s].
Yes I tried GANs (generative adversarial networks) here. No success. Since NIPS2016 I was able to code GANs by myself. A brilliant idea. Generated MNIST digits looked fine, CIFAR images not that.
For generator and discriminator I used MLPs. I think they have a fundamental problem in generating both numeric and categorical data. The discriminator won nearly all the time on my setups. I tried various tricks like truncation the generator output. Clip to known values, many architectures, learn params, noise vec length, dropout, leakyRelu etc. Basically I used activations from hidden layers of the discrimiator as new dataset. At the end they were low 0.28x on CV, too low to contribute to the blend. Haven’t tried hard enough.
Another idea that come late in my mind was a min/max. game like in GAN to generate good noise samples. Its critical to generate good noise for a DAE. I’m thinking of a generator with feature+noiseVec as input, it maximizes the distance to original sample while the autoencoder (input from generator) tried to reconstruct the sample… more maybe in another competition.
Feedforward nets trained with backprop, accelerated by minibatch gradient updates. This is what all do here. I use vanilla SGD (no momentum or adam), large number of epochs, learning rate decay after every epoch. Hidden layers have ‘r’ = relu activation, output is sigmoid. Trained to minimize logloss. In bottleneck autoencoder the middle layer activation is ‘l’ = linear. When dropout!=0 it means all hidden layers have dropout. Input dropout often improve generalization when training on DAE features. Here a slight L2 regularization also helps in CV. Hidden layer size of 1000 works out of the box for most supervised tasks. All trained on GPU with 4-byte floats.
Nice library, very fast, sometimes better than xgboost in terms of accuracy. One model in the ensemble. I tuned params on CV.
I didn’t found a setup where xgboost adds something to the blend. So no used here in Porto.
Nonlinear things failed. That’s the biggest difference to the Otto competition where xgb, nn were great stackers. Every competition has its own pitfalls. Whatever. For me even tuning of linear blending weights failed. So I stick with all w=1.
Everything I’ve done here end-to-end was written in C++/CUDA by myself. Of course I used lightgbm and xgboost C interface and a couple of acceleration libs like cuBLAS. I’m a n00b in python or R like you guys are experts. My approach is still old school and low level. I want to understand what is going from top to bottom. At some time, I’ll learn it, but currently there are just too much python/R packages that bust my head, I’m stick with loop-based code.
All models above can be run on a 32GB RAM machine with clever data swapping. Next to that I use a GTX 1080 Ti card for all neural net stuff.
Some exaflops and kilowatts of GPU power was wasted for this competition for sure. Models run longer than I spend on writing code. Reading all the forum posts also costs a remarkable amount of time, but here my intention was don’t miss anything. At the end it was all worth. Big hands to all the great writers here like Tilli, CPMP, .. really great job guys.
Upsampling, deeper autoencoders, wider autoencoders, KNNs, KNN on DAE features, nonlinear stacking, some feature engineering (yes, I tried this too), PCA, bagging, factor models (but others had success with it), xgboost (other did well with that) and much much more..
That’s it.